Luna Lander RL
The best resource to get started with reinforcement learning is OpenAI’s Gym. As stated on their website, Gym is a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong or Pinball. They’ve abstracted away the work of coding environments for testing reinforcement learning algorithms and created a framework for third parties to develop their own environments. All you need to focus on is managing the agent you want to teach. I highly recommend anyone interested in reinforcement learning to check it out and experiment with it. I suggest starting with classic control problems, such as CartPole-v1. My only complaint is the lack of environments for multi-agent reinforcement learning.
After taking CS639, Sequential Decision Making and Learning, I decided to test my knowledge by tackling the LunarLander-v2 environment. In this environment, our task is to teach a lander to descend and land safely. We can control its three thrusters—left, right, and bottom—in a binary fashion. My approach to this problem was a simple implementation of Actor-Critic with batch learning. Check out my averaged score over the course of my training:
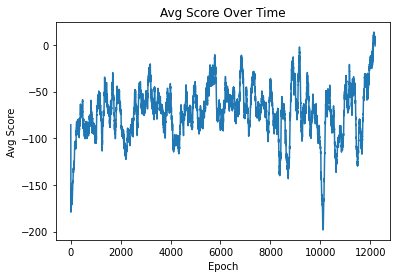
It took a long time, but eventually, it developed a somewhat effective policy. It was able to land correctly about 30% of the time. I think if I revisited and fine-tuned my hyperparameters, I could achieve more consistent results. One thing you’ll notice in this graph is that the performance periodically declines all of a sudden. This is caused by my attempt to encourage more exploration by increasing the chance of choosing a random action. I must admit that the GIF at the top isn’t of my agent. I forgot to record my project, so I borrowed one from the internet. My agent learned a unique approach to this problem: it would swing side to side, realizing that by coming in at the right angle, it could reduce its momentum by hitting its leg against the ground, allowing it to descend at a faster rate. This high-risk, high-reward policy maximized its reward when successful but led to some of the lowest scores possible when it failed, causing the lander to tip over and crash on its head. This explains why it barely averaged above 0 in the end. This is a great example of why I love reinforcement learning: it’s fascinating when it learns to cut corners by exploiting the game engine.